Khi bạn quét mã vạch, làm thế nào để dữ liệu trong mã vạch được dịch thành các chữ cái và số? Các thanh và khoảng trắng bằng cách nào đó đại diện cho các chữ cái và số. Nhưng bằng cách nào mà chúng có thể cho
máy quét mã vạch di động đọc được chúng? Điều thú vị là các loại mã vạch khác nhau thực hiện điều này theo những cách khác nhau.
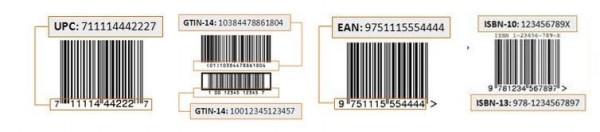
UPC đơn giản nhất có thể. Điều đó một phần là do nó là mã vạch chỉ có số. Chỉ là 0 đến 9. Nhưng ngay cả với UPC khiêm tốn, nó không hoàn toàn đơn giản như vậy. Bên cạnh việc mã hóa các ký tự số, có những vấn đề khác cần giải quyết. Một vấn đề là đảm bảo máy quét giải mã chuỗi số theo đúng trình tự. Làm thế nào để máy quét biết được số đầu tiên từ số cuối cùng, nếu nó được quét sang phải hoặc đảo ngược? Làm thế nào nó có thể phân biệt trái và phải?
1. Nguyên lý chung
Một số mã vạch thực hiện điều này bằng cách sử dụng mẫu bắt đầu và dừng của các thanh và khoảng trắng bắt đầu và kết thúc biểu tượng. UPC làm theo cách khác — và nó thật hấp dẫn. UPC cũng có thanh bắt đầu và dừng, nhưng chúng giống hệt nhau. Bạn có bao giờ nhận thấy hai thanh đó ở trung tâm của UPC không? Họ đánh dấu trung tâm của mã vạch. Các thanh bắt đầu / dừng và khoảng trắng không xác định trái và phải duy nhất. Nó phải được thực hiện theo một cách khác. Đây là cách làm.
2. Nguyên lý của UPC
Nửa bên trái của ký hiệu UPC / EAN mã hóa các số khác với các số ở nửa bên phải. Mẫu các thanh và khoảng trống cho số 3 ở bên trái khác với số 3 ở bên phải. Đây là cách máy quét có thể xác định trái từ phải và giải mã UPC / EAN theo đúng trình tự. Nhưng có một cái gì đó thậm chí còn thú vị hơn về loại biểu tượng này.
UPC chứa 12 chữ số dữ liệu. Bạn có thể nhìn thấy nó với hầu như mọi mã vạch — 12 chữ số có thể đọc được dưới mã vạch, phải không? Chà, không hẳn. UPC mã hóa 13 chữ số dữ liệu.
2.1. Một nguyên lý sáng tạo
Chúng ta hãy xem xét kỹ hơn cấu trúc cơ bản trong giây lát. Xem lại: mỗi ký tự trong số UPC được mã hóa theo mô hình gồm 2 thanh và 2 khoảng trắng. Hai thanh cho mỗi ký tự = 24 thanh. Các ký tự bắt đầu và dừng thêm 4 thanh nữa — 28. Mô hình thanh trung tâm thêm hai thanh nữa. Tổng cộng
máy in mã vạch chuyên dụng in một mã vạch có 30 ô nhịp, 29 ô trống.
Làm thế nào một UPC có thể mã hóa một ký tự thứ 13 mà không có thêm thanh và khoảng trắng? Nó rất thông minh. Chúng ta đã biết rằng các ký tự bên trái khác với các ký tự bên phải. Chúng ta sẽ gọi các ký tự bên trái là ký tự L và các ký tự bên trái là ký tự R. Điều gì sẽ xảy ra nếu có hai loại ký tự L? Chúng tôi sẽ gọi chúng là L-chẵn và L-lẻ. Số chẵn L 1 trông khác với số lẻ L, mặc dù cả hai đều là số một. Chúng tôi sẽ gọi sự khác biệt đó là “ngang giá”.
Các số bên trái của ký hiệu UPC đều là ký tự L-lẻ. Mô hình chẵn lẻ thống nhất của tất cả các số L-lẻ thực sự đại diện cho một chữ số thứ 13, là 0. Số 0 này về mặt kỹ thuật xuất hiện trên tất cả các số UPC dưới dạng tiền tố. Mọi người đôi khi bối rối khi số 0 xuất hiện trong một số hệ thống quét, chữ số 13 luôn ở đó. Đây là biểu đồ cho thấy cách các mẫu chẵn lẻ của các ký tự L đại diện cho số thứ 13.
Mã vạch Đánh số Bài báo Châu Âu (EAN) là một người anh em họ hàng gần của UPC và thường mã hóa 13 chữ số.
Bạn có thể thấy sự khác biệt chẵn lẻ trong các ký tự bên trái trong mã vạch được sử dụng trên hầu hết các sách. Mã vạch này được gọi là Bookland EAN.
Lưu ý 4 thanh cuối cùng ở cuối phía bên trái của mã vạch này, ngay trước mẫu thanh trung tâm. Chúng đại diện cho 2 số 0 được mã hóa. Chú ý rằng cặp thanh cuối cùng hoàn toàn khác với cặp thanh ngay trước chúng. Điều này là do một trong các số 0 là bảng mã L-lẻ và số còn lại là L-chẵn.

















 radiantglobalvn
radiantglobalvn









